Advanced Hybrid Plagiarism & AI-Detection System (WACP)
An institutional-grade academic integrity platform that detects plagiarism and AI-generated content in student project submissions. The system is built on a dual-backend architecture: a CodeIgniter 4 PHP frontend handles authentication, file management, and reporting, while a high-performance FastAPI (Python) microservice runs all NLP and machine learning analysis.
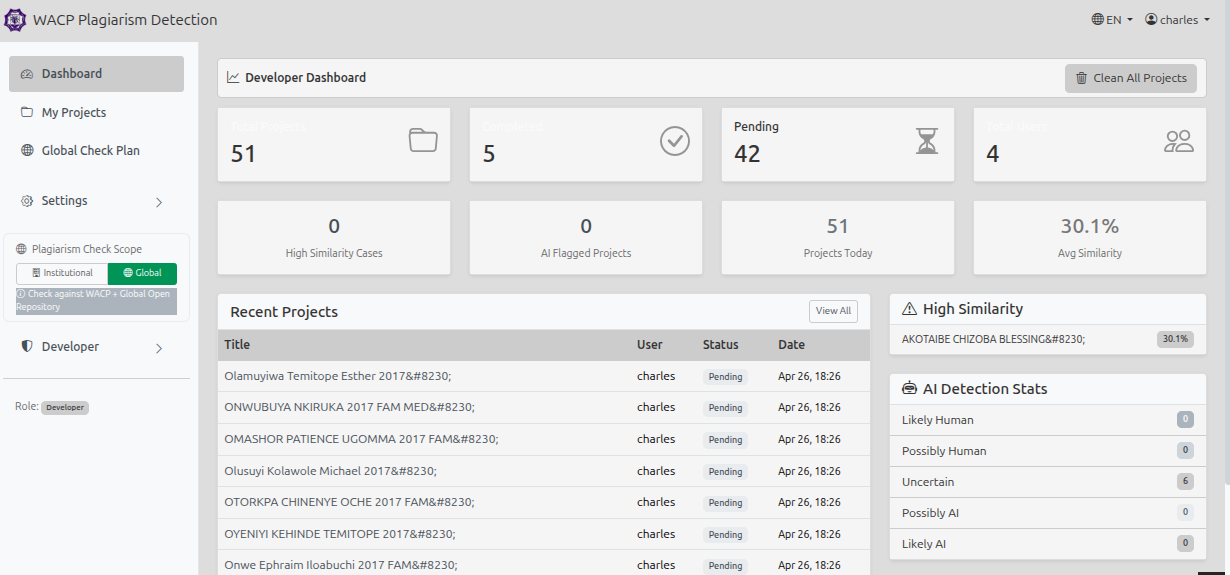
Every submission passes through a 7-stage pipeline: text extraction with positional bounding-box data, preliminary-page stripping (cover, abstract, ToC, bibliography), plagiarism comparison using n-gram fingerprinting and semantic sentence embeddings, a 4-class AI-content classifier, section-level PDF highlighting via PDF.js, auditable report generation, and dual-audience email delivery (full report to admin, summary to student).
A critical design feature is reference isolation: submissions are only compared against verified reference documents (is_reference = TRUE) and previous versions of the same project are excluded via a project_group_id lineage field, eliminating the self-comparison and version-inflation false positives that plague most plagiarism tools. For high-volume use, the system uses Celery task queues with Redis, parallel processing across 8 workers, and Redis-cached fingerprints/embeddings — processing 100 files in 5–10 minutes instead of ~50 minutes. An admin service dashboard allows live management of FastAPI, Celery, and Redis from the browser.
Key Features
27 features built into this project
Challenges & Solutions
Technical problems encountered during development and how each was resolved.
Building a reliable CI4 ↔ FastAPI contract was the first major challenge. The PHP frontend and Python backend had to stay in sync on file paths, project IDs, and webhook callbacks under concurrent load. I solved this with a strict internal API layer and a ServiceStartupFilter that auto-boots all backend services when the CI4 app first loads, eliminating the "backend not running" failure state.
The accuracy problem was harder. A pure n-gram fingerprint approach caught exact copies but missed paraphrased content entirely. Layering sentence-transformer semantic embeddings on top added paraphrase detection, but this introduced a new problem: the system was flagging re-submitted versions of the same project as plagiarised against themselves. I designed the reference isolation model (is_reference flag + project_group_id lineage) to eliminate self-comparison and version inflation as structural guarantees rather than threshold tuning.
AI-content detection required a completely separate heuristic pipeline. Detecting GPT/Claude output is straightforward — low perplexity and high uniformity are reliable signals — but detecting QuillBot-paraphrased AI text is much harder because the surface statistics change. I extracted 50–200 features covering rare synonym overuse, sentence-length uniformity, function-word ratios, and readability stability, feeding them into a Gradient Boosting 4-class classifier. All results are expressed probabilistically ("Likely AI-paraphrased, 71% confidence") to comply with institutional ethics requirements.
Performance collapsed under bulk submissions. Sequential processing took ~30 seconds per file, so 100 files meant 50 minutes and frequent timeouts. I rebuilt the analysis path around Celery with three dedicated queues, Redis caching for fingerprints and embeddings, and ThreadPoolExecutor for in-process parallelism — cutting 100-file batches to 5–10 minutes with automatic retry on failure.
More Projects
Other work in the PHP category
Charymeld Adverts Platform
A production-ready classified advertising platform built with Laravel 11, supporting a full three-sided market…
CodeSphere — LMS & Training Platform
A fully-featured Learning Management System (LMS) built with CodeIgniter 4 and deployed at training.teamodigit…
TeamO Ranch — Farm & Agribusiness Website
TeamO Ranch is a sustainable farm e-commerce and service-booking website for an agricultural business based in…